Understanding AWS S3 Tables Integration with Apache Iceberg
Amazon S3 has been a go-to storage layer for creating cost-efficient and scalable data lakes for years. Nonetheless, conventional S3-based data tables built on formats such as Hive or Glue, are not equipped with strong data management functionality such as ACID transactions, schema evolution, and time travel.
This is where Apache Iceberg comes in.
In this blog, we’ll explore what AWS S3 Tables are, why Apache Iceberg is a game-changer for managing them, and how to integrate both to build a high-performance, cloud-native data lake. Amazon S3 Table Buckets are a specialized type of S3 bucket designed specifically to store tabular datasets as native S3 resources. These buckets manage both data and metadata as objects, making them optimized for analytics workloads.
To enhance performance and lower expenses, AWS conducts auto background maintenance operations like file compaction and garbage collection. This lightens the operational load and makes it easier to manage massive tabular data.
To use the tables stored in these buckets, you can integrate them with analytics applications that have support for Apache Iceberg, an open format for tables for high-performance, transactional data lake operations.
Table buckets are also easily integrated with AWS analytics services through the AWS Glue Data
Catalog, allowing easy querying through Amazon Athena, AWS Glue, and Amazon Redshift. They can also work with open-source engines like Trino, Presto, and Apache Spark through the Amazon S3 Tables Iceberg Catalog and REST endpoint.
Key Features of Amazon S3 Tables with Apache Iceberg
Now that we’ve understood the foundation of S3 Tables and Iceberg, let’s break down the key features that make this integration a powerful choice for modern data lake architectures.
Purpose-Built for Tabular Data
S3 Table Buckets are designed specifically for storing tabular datasets as native S3 objects. These buckets offer 10x higher transactions per second (TPS) and 3x faster query performance than general-purpose S3 buckets, while retaining the same durability, scalability, and availability as standard Amazon S3. This positions them well for high-volume analytics workloads with little management overhead.
Apache Iceberg Built-in Support
S3 Table Buckets store tables in Apache Iceberg format, which brings cutting-edge data lake capabilities. Iceberg supports evolution of schema and partition evolution, so you can change your data structure without re-writing queries. It provides ACID-compliant transactions, which assist in handling concurrent writes securely and in maintaining consistency. Iceberg also offers time travel, which allows you to roll back to past table states—helpful for debugging or reprocessing.
Improved Performance with Iceberg Internals
Apache Iceberg enhances performance with its manifest files and metadata layer architecture, which facilitate efficient tracking of files and pruning. In contrast to conventional formats that rely on directory scanning, Iceberg utilizes metadata to find the correct files more quickly, lowering query latency and I/O overhead. Hidden partitioning features eliminate the necessity for folder-based partition logic and automate data management, enhancing compatibility with many engines.
Automatic Table Optimization
S3 Tables are automatically optimized by ongoing background maintenance activities. They involve compaction of small files into one large file, snapshot cleanup to delete previous versions, and delete of unreferenced files to clean storage clutter. Automation enhances query performance and minimizes storage expense, all without increasing the workload for managing large datasets. You can also set up optimization behavior for a given table or bucket to accommodate particular workloads.
Access Management & Security Controls
Access to S3 Tables is securely governed with AWS Identity and Access Management (IAM) and Service Control Policies (SCPs). The service has its own namespace (s3tables) so fine-grained access rules different from the standard S3 buckets are possible. Public access is consistently prohibited—Amazon S3 Block Public Access is always enabled for table buckets. You can set policies on a per-table, namespace, or per-bucket basis to suit your organizational security needs.
Integration with AWS Analytics Ecosystem
S3 Tables natively integrate with AWS analytics services using the AWS Glue Data Catalog, which enables easy discovery and querying of data. AWS Glue crawlers can automatically scan S3 buckets and create tables in the Glue Data Catalog, which AWS Athena then uses for querying. After you integrate, you can analyse, create dashboards, or train machine learning models using Amazon Athena, Amazon Redshift, AWS Glue, Amazon QuickSight, and Amazon SageMaker Lakehouse directly on your Iceberg tables stored in Amazon S3.
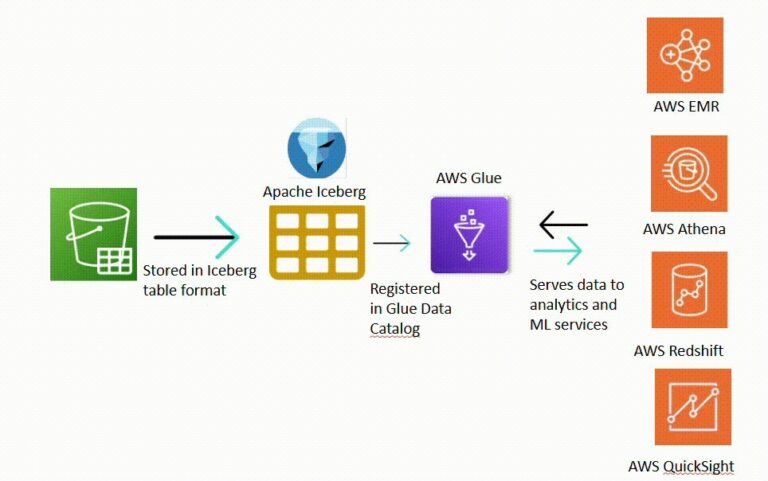
Figure 1: S3 Table Buckets Integration with Apache Iceberg and AWS Analytics Services
Use Cases
Modern Data Lakes
Organizations looking to modernize their data lake infrastructure can leverage S3 Tables with Apache Iceberg for scalable, cost-efficient storage with built-in performance tuning, schema evolution, and ACID guarantees.
Real-Time Analytics
S3 Table Buckets offer high TPS and faster query response, making them ideal for near real-time dashboards and interactive analytics through Amazon Athena or Redshift.
Machine Learning Workflows
With native integration into services like Amazon SageMaker and AWS Glue, data scientists can easily access clean, versioned datasets for model training and feature engineering.
Compliance and Auditing
Iceberg’s time-travel capabilities and versioned snapshots allow teams to trace data changes over time, essential for debugging, auditing, and satisfying regulatory requirements.
ETL Pipelines with Spark or Trino
Open-source query engines such as Apache Spark, Trino, or Presto can directly read and write to Iceberg-formatted S3 Tables, allowing teams to run distributed data transformation jobs efficiently.
Conclusion
Amazon S3 Table Buckets combined with Apache Iceberg mark a significant shift in how tabular data is stored, accessed, and managed in the cloud. By embracing Iceberg’s powerful metadata and transaction model, S3 Tables provide a cloud-native, high-performance, and secure solution for building modern data lakes.
Whether you’re aiming for faster analytics, robust governance, or cost-effective scaling, this integration simplifies your architecture while enhancing performance. With support for time travel, schema evolution, and automated optimization, S3 Tables with Iceberg empower teams to unlock deeper insights from their data, without compromising on flexibility or control.
By – Madhuri Jha